Modular-Cam: Modular Dynamic Camera-view Video Generation with LLM
Abstract
Text-to-Video generation, which utilizes the provided text prompt to generate high-quality videos, has drawn increasing attention and achieved great success due to the development of diffusion models recently. Existing methods mainly rely on a pre-trained text encoder to capture the semantic information and perform cross attention with the encoded text prompt to guide the generation of video. However, when it comes to complex prompts that contain dynamic scenes and multiple camera-view transformations, these methods can hardly decompose the information of different scenes and fail to change the scene with the corresponding camera-view smoothly. To solve the above problems, we propose a novel method called Modular-Cam. Specifically, to better understand the provided complex prompt, we utilize a large language model to analyze user instructions and decouple them into multiple scenes and transition actions. To generate the video of dynamic scenes that matches the given camera-view, we adopt widely-used temporal transformer into the diffusion model to ensure continuity within a single scene, and propose a CamOperator based on modular network that finely controls the camera movement. Additionally, we propose AdaControlNet, which utilizes ControlNet to ensure consistency across scenes and adaptively adjusts the color tone of the generated video. Extensive qualitative and quantitative experiments prove our proposed Modular-Cam's strong capability of generating multi-scene videos together with its ability to achieve fine-grained control of camera movements.
Method
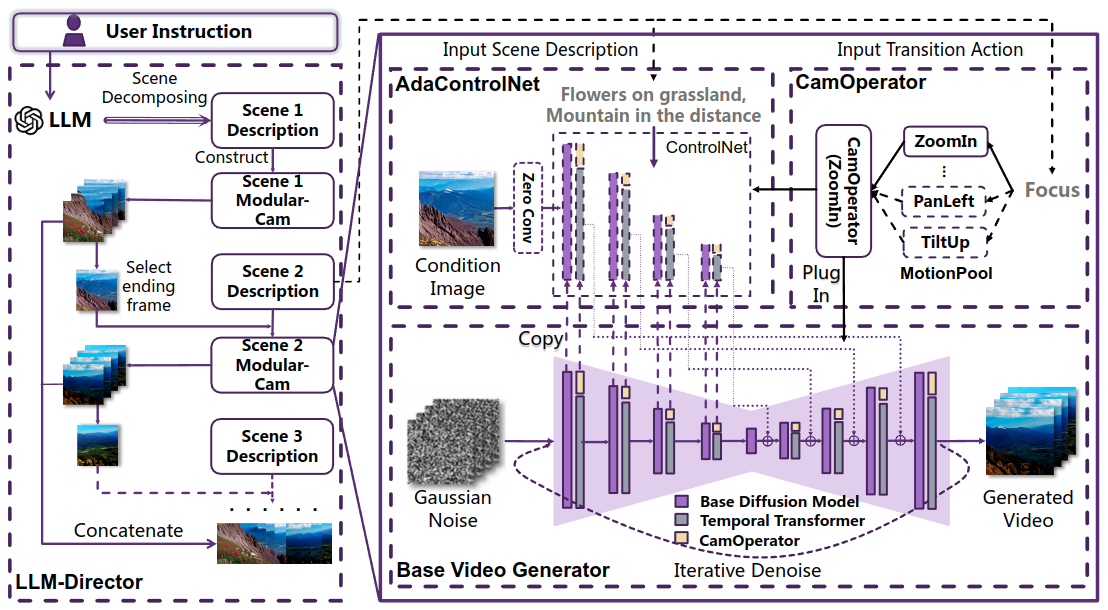
In this work, we present a novel Modular-Cam framework to address the aforementioned problems. Specifically, to provide a deep understanding of the user instructions, we propose an LLM-Director which utilizes a large language model (LLM) to analyze the instructions and decompose them into multiple scenes and transition actions. The obtained disentangled information is crucial for the generation of individual scenes and entire videos. Based on T2I diffusion models, we conduct a base video generator by inserting temporal transformer layers, transferring information across frames, and maintaining the continuity of the generated video within a single scene. We further propose a CamOperator module, which is a series of LoRA layers added on the base generator to ensure fine-grained control of the camera movements. For each motion pattern, i.e., ZoomIn, PanLeft, etc., a corresponding CamOperator module is trained. LLM will select which CamOperator module to use from the operation pool based on the transition action it acquires. Besides, these CamOperators can function as modular components. For complex camera view transformations, it is not necessary to retrain each of the CamOperators but rather utilize the existing modular operators to combine them. Benefitting from the modularity, we can easily plug them in at different situations, which greatly enhances the scalability of the model. To improve the consistency across multiple scenes, we adopt an autoregressive method and propose AdaControlNet, which introduces the ending frame of the last scene as the control information for the generation of the current scene and adaptively adjusts the color tone of the videos. Consequently, guided by the last scene, the transition between adjacent scenes will be smooth. We concatenate the video clips for each scene sequentially, deriving the final multi-scene dynamic camera-view video, which completes the end-to-end procedure.
Results
| "Beginning with a beach scene, the camera gradually draws in closer as waves lap against the reef. Then the camera slowly pans right and a large area of sea is revealed." | "Beginning with a view of a modern city street, the camera gradually moves back, with the houses on both sides moving back too. Finally, the camera lifts up and gives a shot of the blue sky." | "Starting with a close up shot of the flowers in the meadow, the camera slowly moves to the right to focus on the mountain peaks in the distance and gradually draws in closer. The camera then continues to move to the right as the mountain and the lake mirror each other." | "The camera pans left to reveal a large area of desert, then the camera advances to give a better view of the dunes in the distance. Finally, the camera tilts down to focus on the sand at the feet." |
| "Starting with a distant shot of a field with blue sky, the camera gradually focuses on a house in the distance. The camera then gradually pans right to reveal a large field and the house moves out of view." | "Starting in a submarine world, the camera slowly moves left to reveal a variety of marine life. Then the camera moves forward, aiming at a large area of water plants in the distance." | "The camera gradually zooms in to focus on a running rabbit on the grassland. Then the camera pans left to give a panoramic shot, while the rabbit stops moving." | "Starting with an indoor shot, the camera moves left to reveal a big window. Then the camera gradually zooms in, focusing on the trees outside." |